
Real world example of reducing allocations using Span<T> and Memory<T>

I have been planning to write this post for a few months now but always seem to have found something new to add. This all started when I decided to look at the RabbitMQ .NET Client source code to see if I could make improvements to the asynchronous logic and add support for System.IO.Pipelines. During that exploration I saw some opportunities for improvements that could be made to memory allocations. This was quite a learning project for myself as I both had to relearn a lot of things I had already learned and a lot of new things as well.
Brief introduction to the AMQP 0.9.1 Protocol
RabbitMQ uses the AMQP 0.9.1 protocol by default. In overly broad terms, every AMQP operation is defined as a command. Before transmission, commands are split into frames of a specified maximum size (often dictated by the server), and these frames are then serialized to bytes for transmission on the wire when the client and server communicate. AMQP uses network byte order representation/big-endian for its data types so you have to be careful when serializing them on little-endian systems like Windows, so you don't corrupt data and the client can be interoperable with other operating systems. Now there are certain nuances to the protocol, and I am oversimplifying things here, but this is the gist of how the AMQP protocol works.
Binary Serialization
To serialize data to/from RabbitMQ we need to be able to translate data into a binary format. This is called serialization and as I mentioned above, RabbitMQ uses network-byte-order.
Previously the library used a class called NetworkBinaryReader which inherited from BinaryReader and overrode certain methods. BinaryReader is a very old class in the .NET BCL and does not take endianness into account, and the library also assumed that it was running on little-endian systems so quite a lot of overhead went into serializing doubles and floats.
Here is an example of how NetworkBinaryReader previously implemented the ReadDouble method:
public override double ReadDouble()
{
byte[] bytes = ReadBytes(8);
byte temp = bytes[0];
bytes[0] = bytes[7];
bytes[7] = temp;
temp = bytes[1];
bytes[1] = bytes[6];
bytes[6] = temp;
temp = bytes[2];
bytes[2] = bytes[5];
bytes[5] = temp;
temp = bytes[3];
bytes[3] = bytes[4];
bytes[4] = temp;
return TemporaryBinaryReader(bytes).ReadDouble();
}
This was changed to get rid of the temporary MemoryStreams (used in the TemporaryBinaryReader method above) and byte arrays to reduce allocations.
Here is an example of how we are now reading Double from a ReadOnlySpan<byte>:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
internal static double ReadDouble(ReadOnlySpan<byte> span)
{
if (span.Length < 8)
{
throw new ArgumentOutOfRangeException(nameof(span), "Insufficient length to decode Double from memory.");
}
uint num1 = (uint)((span[0] << 24) | (span[1] << 16) | (span[2] << 8) | span[3]);
uint num2 = (uint)((span[4] << 24) | (span[5] << 16) | (span[6] << 8) | span[7]);
ulong val = ((ulong)num1 << 32) | num2;
return Unsafe.As<ulong, double>(ref val);
}
This resulted in a dramatic decrease in allocations as well as CPU savings. Here is an example of BenchmarkDotNet benchmarks I created for verification.
Double
| Method | Runtime | Mean | Error | StdDev | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|
| ReadBefore | .NET 4.8 | 150.351 ns | 1.2760 ns | 0.9962 ns | 0.1147 | - | - | 361 B |
| ReadAfter | .NET 4.8 | 8.116 ns | 0.1166 ns | 0.1090 ns | - | - | - | - |
| ReadBefore | Core 3.1 | 67.239 ns | 0.9648 ns | 0.8553 ns | 0.0739 | - | - | 232 B |
| ReadAfter | Core 3.1 | 4.080 ns | 0.1625 ns | 0.1441 ns | - | - | - | - |
| WriteBefore | .NET 4.8 | 160.946 ns | 4.3261 ns | 4.0467 ns | 0.1249 | - | - | 393 B |
| WriteAfter | .NET 4.8 | 7.788 ns | 0.1187 ns | 0.1110 ns | - | - | - | - |
| WriteBefore | Core 3.1 | 84.995 ns | 2.0234 ns | 2.6311 ns | 0.0815 | - | - | 256 B |
| WriteAfter | Core 3.1 | 3.576 ns | 0.0498 ns | 0.0465 ns | - | - | - | - |
Single
| Method | Runtime | Mean | Error | StdDev | Median | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| ReadBefore | .NET 4.8 | 142.165 ns | 2.0497 ns | 1.9172 ns | 141.090 ns | 0.1147 | - | - | 361 B |
| ReadAfter | .NET 4.8 | 2.322 ns | 0.0520 ns | 0.0406 ns | 2.328 ns | - | - | - | - |
| ReadBefore | Core 3.1 | 65.098 ns | 1.3230 ns | 1.4705 ns | 64.897 ns | 0.0739 | - | - | 232 B |
| ReadAfter | Core 3.1 | 1.772 ns | 0.0738 ns | 0.0789 ns | 1.771 ns | - | - | - | - |
| WriteBefore | .NET 4.8 | 151.188 ns | 1.4721 ns | 1.2293 ns | 150.984 ns | 0.1249 | - | - | 393 B |
| WriteAfter | .NET 4.8 | 3.101 ns | 0.0603 ns | 0.0564 ns | 3.101 ns | - | - | - | - |
| WriteBefore | Core 3.1 | 75.557 ns | 0.9762 ns | 0.9131 ns | 75.431 ns | 0.0815 | - | - | 256 B |
| WriteAfter | Core 3.1 | 1.188 ns | 0.0991 ns | 0.2697 ns | 1.093 ns | - | - | - | - |
Serializing data and reusing buffers
Serializing data types is one thing. Serializing the AMQP data structures composed of that data is another thing. Messages are serialized into what's called Frames. Frames consist of a frame header, channel number, frame size and then the eventual frame payload (our data) and ends with a frame-end marker byte.
This brings up an interesting problem, which stems from the frame size. The frame size appears in the structure before the actual payload does, which makes sense because we need the consumers of the protocol to know how many bytes are in the payload they are about to read. But, since our payload can contain all sorts of data as well as header properties, and data types are serialized differently, it's hard for us to know the size of the serialized payload before we have actually serialized all the data in the message.
The obvious solution: MemoryStream
Previously, this was solved in a way many of us would think of. The client library created a MemoryStream, which was as the output stream for the NetworkBinaryWriter class used to serialize the data. After all the data had been written, it was easy to keep track of how many bytes had been written to the MemoryStream, seek back to the correct header position and write the payload size. Job done!
This method did its job, and most importantly did it correctly, but it had the drawback that the entire frame had to be buffered as it was being serialized, and as the MemoryStream grew bigger, new backing arrays needed to be allocated, memory copied etc. until the entire frame was correctly serialized and fit into the buffer, and eventually the resulting array was output to the network.
A better solution: MemoryPool<byte>
This was a noticeably big part of where allocations were being made so it became one of the focus points. When I looked at the code I figured, since I already had all the data, that I didn't need to serialize all of it to know how big it would be. I could simply walk through the data structure and calculate the required buffer size. We know a byte is one byte, a float is four bytes, int is four bytes etc. The biggest problem was strings. Given an arbitrary string, how do I know how many bytes it'll occupy when it's encoded using UTF8? Luckily for us, such a method already exists (Encoding.GetMaxByteCount), so that problem was solved as well.
So, what I decided to do, was to simply calculate how big each frame would need be at minimum when serialized, utilize System.Buffers.MemoryPool<T> from the System.Memory NuGet packages to fetch a pooled byte array of the minimum size, and then serialize the data directly to that pooled array, write it to the network socket and eventually return the array to the pool to be reused later. This would allow the client to eliminate any memory churn when serializing the data since data would be serialized to reusable byte arrays.
Now, you may wonder why I didn't use one of the many libraries that provide implementations of MemoryStream that reuse pooled arrays, like Microsoft.IO.RecyclableMemoryStream? The answer is future proofing! Moving to System.Memory gives the library access to Memory<T> and Span<T>, which are a mainstay in .NET Core, and will make the migration to System.IO.Pipelines a lot easier. So, stay tuned because there is even more good stuff coming in later versions :)
Armed with this knowledge and idea, let's take a closer look at some of the improvements made and the impact it had!
Converting strings to UTF8 bytes
One of the first things I noticed was that when strings were being serialized, they were converted directly to a UTF8 byte array. Obviously, this will create a new array to contain the UTF8 bytes. However, strings can also be serialized to an existing array and given an offset to where to start to write the bytes and we'll also know how many bytes are eventually written. This of course fit in extremely well with the pooled array idea.
This is how strings were serialized to a stream before:
public static void WriteShortstr(NetworkBinaryWriter writer, string value)
{
byte[] bytes = Encoding.UTF8.GetBytes(value);
writer.Write((ushort) bytes.Length);
writer.Write(bytes);
}
And this is how it's now serialized to a Memory<byte>
public static int WriteShortstr(Memory<byte> memory, string val)
{
int stringBytesNeeded = Encoding.UTF8.GetByteCount(val);
if (MemoryMarshal.TryGetArray(memory.Slice(1, stringBytesNeeded), out ArraySegment<byte> segment))
{
memory.Span[0] = (byte)stringBytesNeeded;
Encoding.UTF8.GetBytes(val, 0, val.Length, segment.Array, segment.Offset);
return stringBytesNeeded + 1;
}
throw new WireFormattingException("Unable to get array segment from memory.");
}
Now, granted, the new code is a little more verbose, but it is MUCH more efficient. Here is an example benchmark converting the first "Lorem Ipsum" paragraph to UTF8 bytes.
| Method | Runtime | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| GetByteArray | .NET 4.8 | 1,115.2 ns | 13.68 ns | 12.79 ns | 1.00 | 0.2823 | - | - | 891 B |
| WriteToMemory | .NET 4.8 | 625.6 ns | 5.23 ns | 4.89 ns | 0.56 | 0.0076 | - | - | 24 B |
| GetByteArray | .NET Core 3.1 | 234.0 ns | 4.11 ns | 3.64 ns | 1.00 | 0.2828 | - | - | 888 B |
| WriteToMemory | .NET Core 3.1 | 157.0 ns | 2.36 ns | 2.09 ns | 0.67 | 0.0076 | - | - | 24 B |
Arrays
As we have seen, the benefits of pooling and reusing arrays on code hot paths can be quite dramatic. This is mostly the result of freeing up our precious CPU cycles from being used by the Garbage Collector, cleaning up all our temporary objects. Having a garbage collector is one of the benefits of a managed language such as C#, but not having to use the Garbage Collector is even better.
I was able to take advantage of pooled arrays in the RabbitMQ client in several places. One of them was in the serialization as I mentioned above, where we could estimate the minimum amount of memory we'd need to serialize a frame, "rent" that amount of memory from our array pool, serialize the data directly into the array instead of using a MemoryStream + BinaryWriter object, and then send that array directly to the network Socket where it was sent to the server. Then we could return the array to the pool, rinse, and repeat.
But what about the messages received from the server? Could I take advantage of them there.
YES!
After thinking about it for a while, I realized the the message payloads were being sent and received as byte arrays (byte[]). After talking it over the the RabbitMQ client maintainers, we decided that we'd make the change to have the message payloads represented as Memory<byte> instead. That allows us to use pooled arrays for messages received, copy the payload into another pooled array before being sent to the message event handlers, and then we could return them to the pool once the consumers had processed the messages!
Thankfully this was easy to solve using the MemoryPool<T> type. It allows us to easily rent and return pooled arrays using the IDisposable pattern. To give you an example of how to use it, let's imagine that we need calculate the SHA1 hash for a UTF8 string. As an example we'll use the same first "Lorem Ipsum" paragraph as an example.
Using the easy and convenient way:
private SHA1 hasher = SHA1.Create();
public byte[] GetByteArray()
{
return hasher.ComputeHash(Encoding.UTF8.GetBytes(LoremIpsum));
}
Using MemoryPool<byte>:
private SHA1 hasher = SHA1.Create();
// Emulating a reusable pooled array to put the calculated hashes into
private Memory<byte> hashedBytes = new Memory<byte>(new byte[20]);
public Memory<byte> WriteToMemoryWithGetByteCount()
{
int numCharactersNeeded = Encoding.UTF8.GetByteCount(LoremIpsum);
// Let's use pooled memory to put the converted UTF8 bytes into. This is
// wrapped in a using statement so once we have finished calculating the hash,
// we will return the array to the pool, since it implements IDisposable.
using (IMemoryOwner<byte> memory = MemoryPool<byte>.Shared.Rent(numCharactersNeeded))
{
if (MemoryMarshal.TryGetArray(memory.Memory.Slice(0, numCharactersNeeded), out ArraySegment<byte> segment))
{
Encoding.UTF8.GetBytes(LoremIpsum, 0, LoremIpsum.Length, segment.Array, segment.Offset);
hasher.TryComputeHash(segment, hashedBytes.Span, out int _);
return hashedBytes;
}
throw new InvalidOperationException("Failed to get memory");
}
}
Now again, the code is more verbose, but it is much more memory friendly.
| Method | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|
| ByteArray | 2.378 us | 0.0241 us | 0.0226 us | 1.00 | 0.3090 | - | - | 984 B |
| MemoryPool | 2.244 us | 0.0219 us | 0.0205 us | 0.94 | 0.0076 | - | - | 24 B |
Results!
After going a few rounds on this, finding more places where I could put this to practice, and submitting several PRs, this work was finally released in the 6.0.0 release of the RabbitMQ .NET Client NuGet package. I decided to write a small program to see the result and run it through the JetBrains dotMemory profiler to see the result.
The program did the following:
- Set up two connections to RabbitMQ, one to publish messages and another to receive them.
- Used publisher confirms
- Sent 50.000 messages, in bathes of five hundred messages at a time.
- Used 512 byte and 16kb message payloads to test memory usage.
- Ran until it had received those 50.000 messages back.
Here are the results:
| Payload Size (KB) | Memory Allocated Before (MB) | Memory Allocated After (MB) | Savings |
|---|---|---|---|
| 512 | 470.03 | 99.43 | 78.85% |
| 16,384 | 7,311.36 | 99.41 | 98.64% |
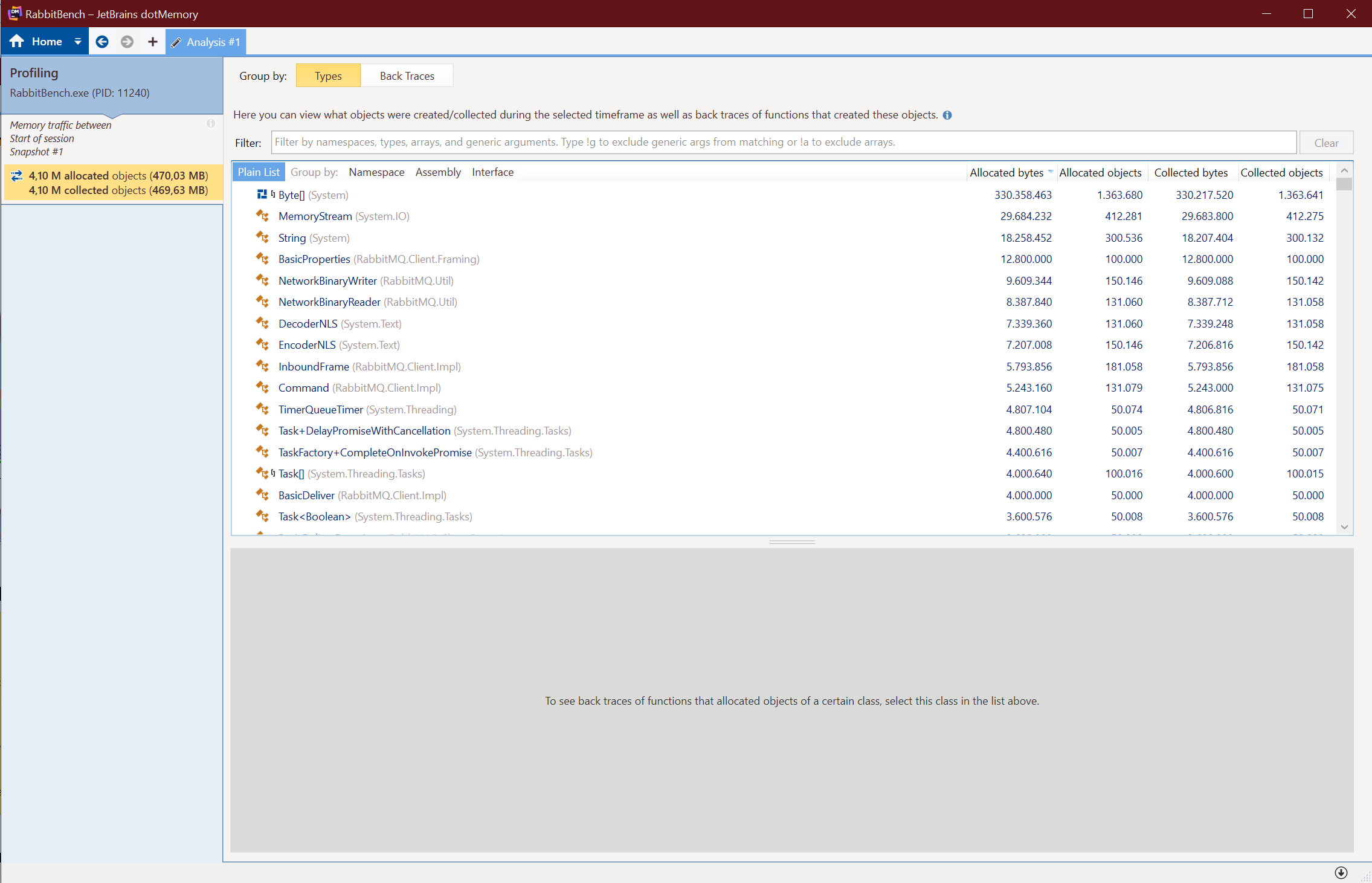
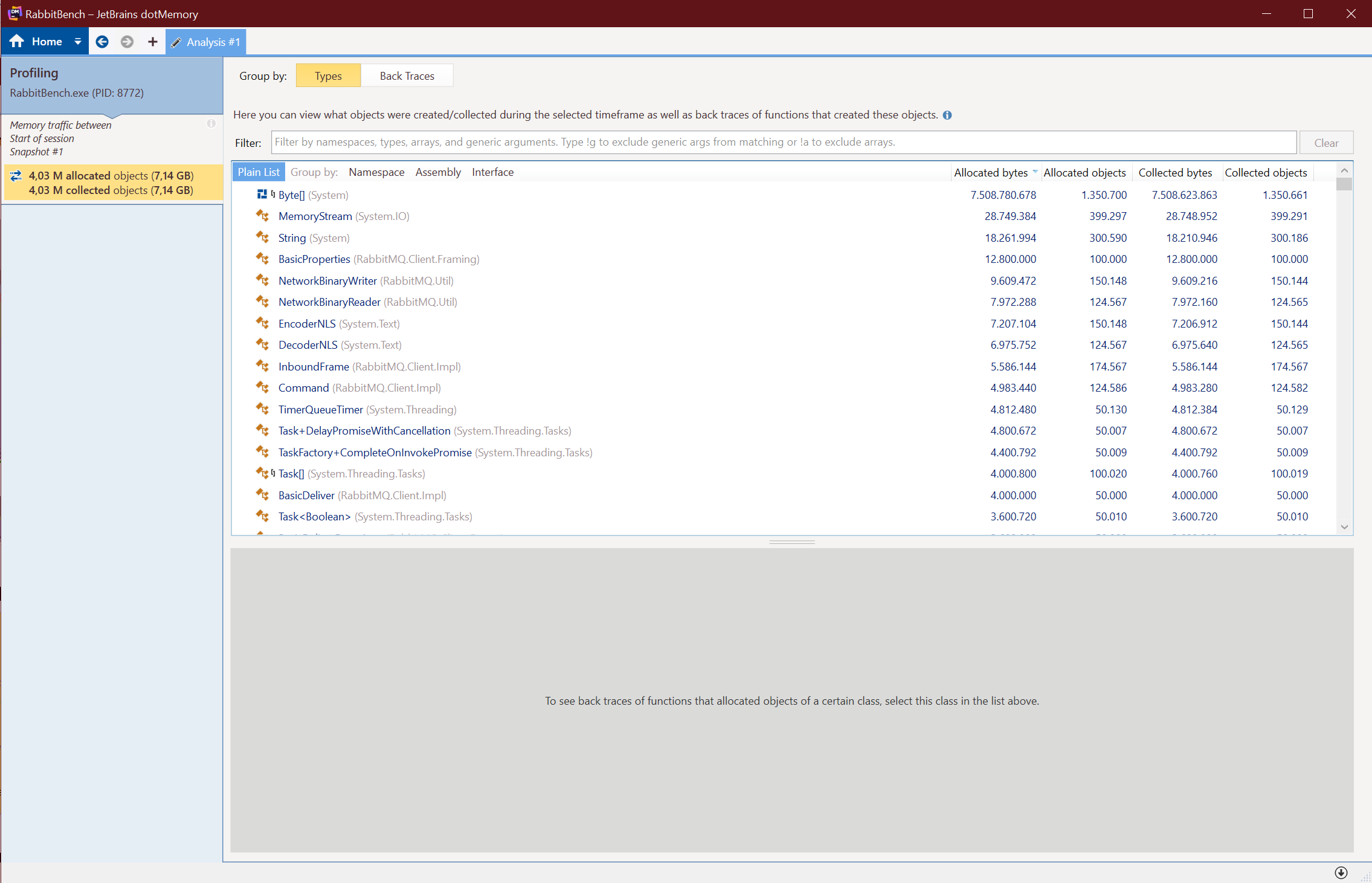
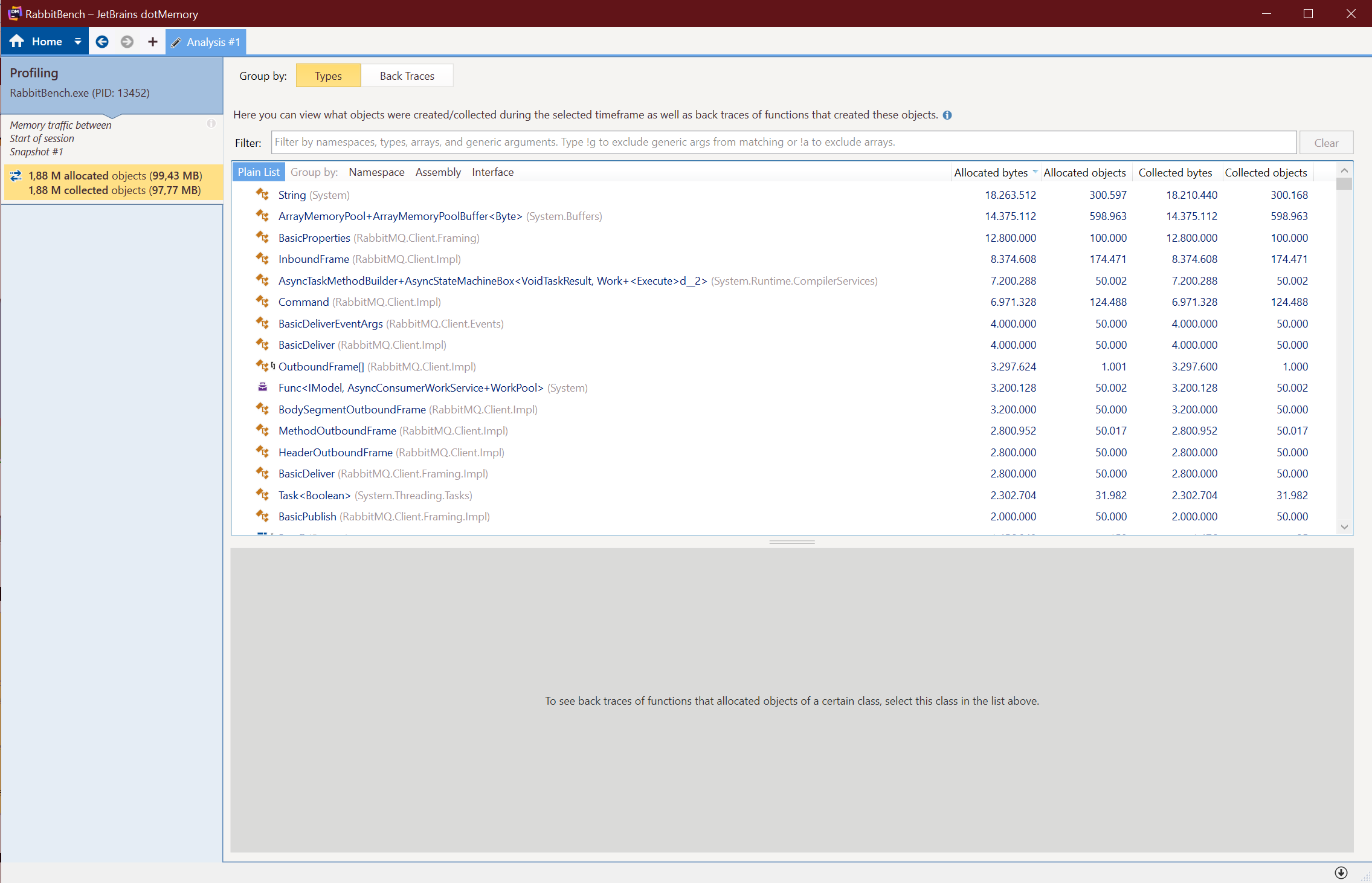
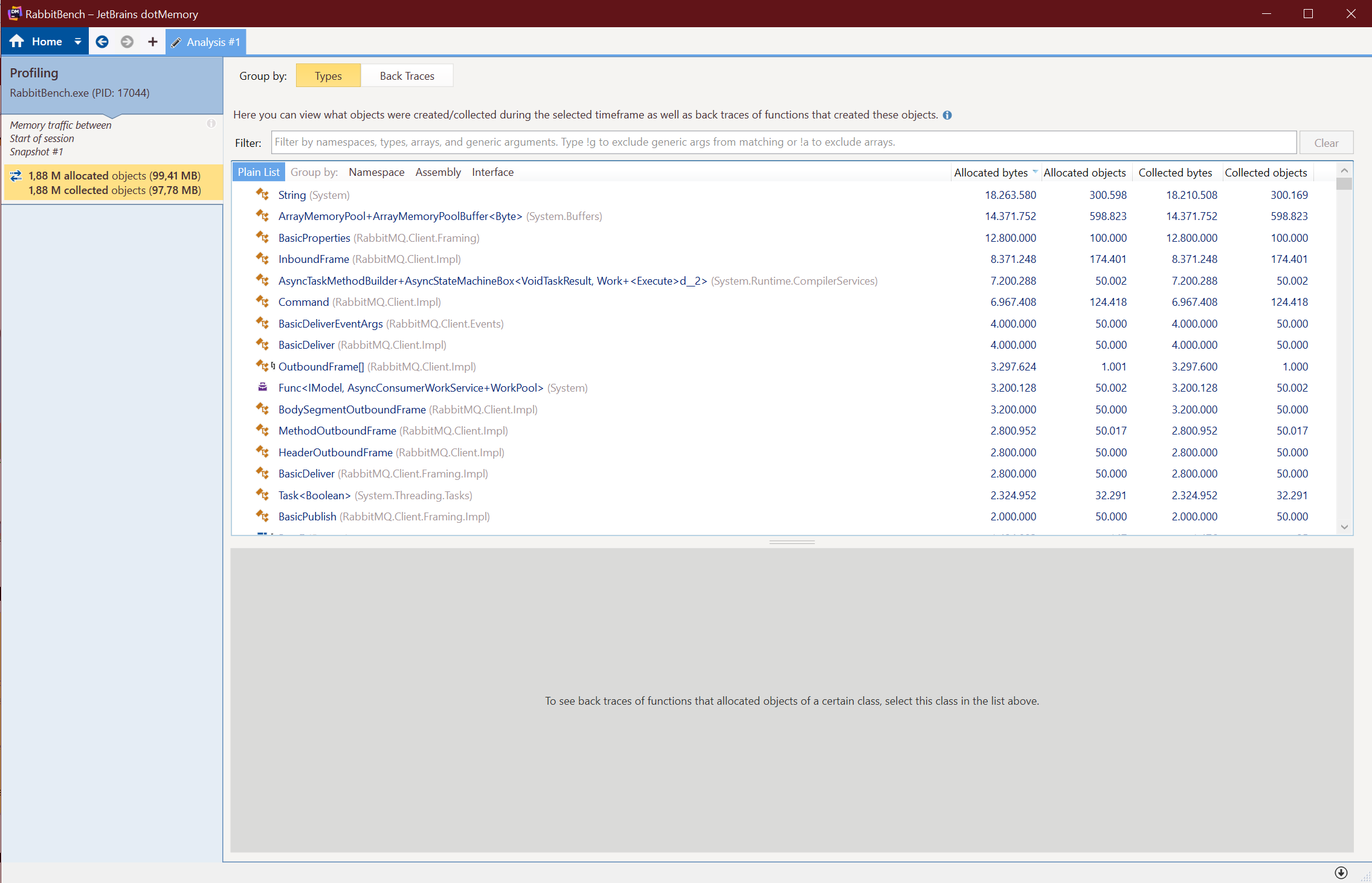
As you can see, the memory usage when sending and receiving the events is now pretty much constant, regardless of the payload size. This is a massive improvement and frees up a lot of valuable CPU cycles and memory churn for other tasks.
What really made me happy with this release, was the fact that the API change only very slightly, and in most cases required little or no changes at all for the consumers of the package.
This is however not the end of this performance work by any means. There are more improvements in the pipeline (hint hint) that are sure to bring even more gains, for the benefit of everyone, so stay tuned :)